
Kafka最初是有Linkedin公司研发的,是一个分布式流处理系统,流处理系统提供了推送消息和订阅消息功能,分布式提供了高容错、并发处理消息机制。
Kafka作为一个热门的消息队列中间件,具有高效可靠的异步消息传递机制,应用场景很多
日志处理与分析
推荐数据流
系统监控预警告
CDC(数据变更捕获)
系统迁移
事件追溯
消息队列

系统架构
整体简单说就是生产者发送消息给kafka,消费者拉取消息。
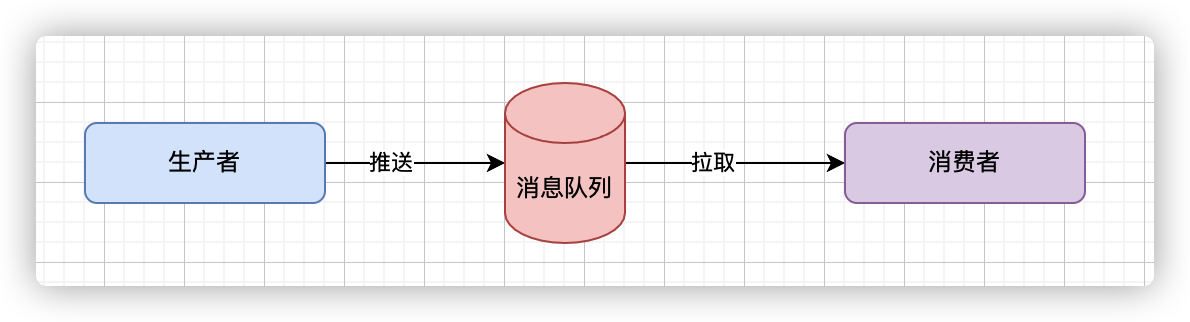
不过kafka对于这三端做了很多高可用的方案,来提升并发量。下面先介绍下Kafka中各个组件:
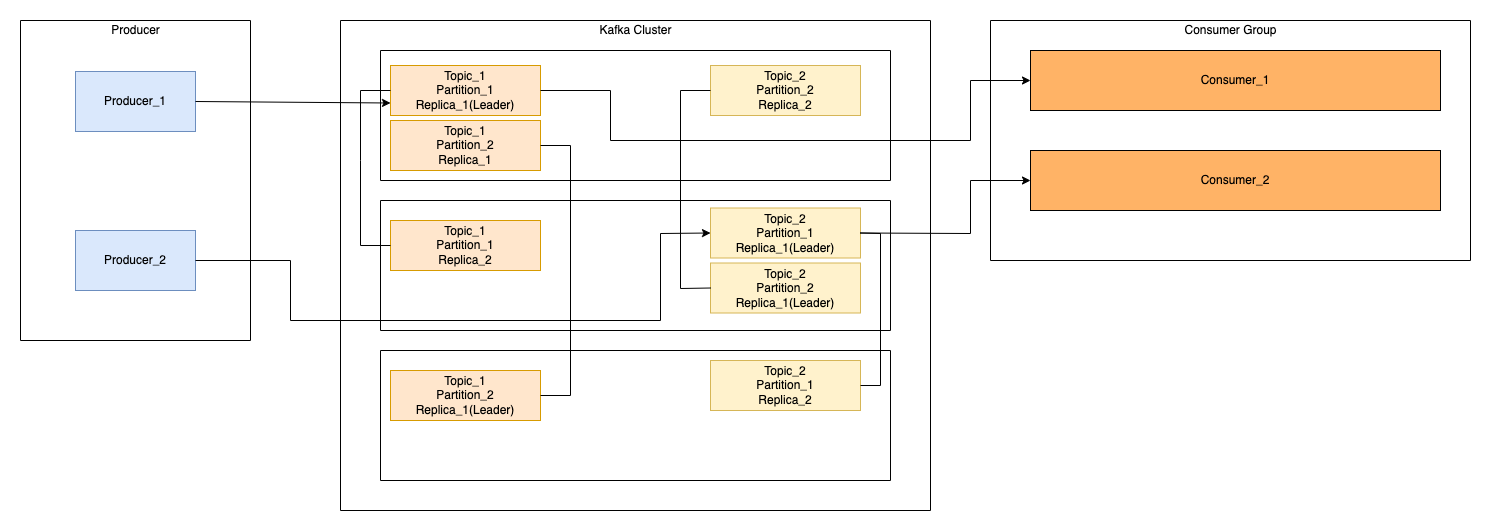
- Producer: 生产者,用于发送消息到Kafka服务端
Broker:Kafka消息服务端,多个Broker组成Kafka服务端集群。每个Broker中会有一个或N个partition。
Topic:消息主题,一个主题就是一组消息的队列,这个消息队列保存这一类型的消息,topic中实际有一个或N个Pratition,实际消息是存储在一个Topic下Partition中。一个Topic如果有多个Partition,则消息是无序的,如果一个Topic下只有一个Partition,则消息是有序的,因为一个Partition中的消息是有序的。
Partition:是Topic在物理上的分片。一个Topic可以有多个Partition,每个Partition内的消息是有序的队列。Partition可以有副本(Replica)来保证高可用性。
Consumer:消费者,负责从Kafka中拉取消息。
Consumer Group:消费组,多个Consumer使用同一个ConsumerID称之为一个消费组,每条消息只能被Consumer Group中一个Consumer消费,但可以被多个Consumer Group消费。
Replica:Partition的副本,用来保证高可用性,提高容灾能力。每个Partition的副本会均匀的分不到不同的Broker上。如果Partition副本的Leader出现问题,则会从其他的副本中选举出新的副本作为Leader。
Controller:Kafka集群中的单独一台服务器,主要负责处理Parition的Leader出现异常后,选举新的副本为Leader。
Zookeeper:管理Kafka的Broker注册等各个组件的信息。
基于上面各个组件,得出下面这张图
高性能
Kafka的高性能不仅仅因为架构的分布式,还有消息批量发送、IO顺序读写、PageCache加速消息读写、零拷贝技术等。
批量消息提升数据处理能力
Kafka内部消息都是一“批”为单位处理,当kafka客户端实现消息发送时,采用的时异步批量发送机制。
当我们调用send() 发送消息时,不管是同步还是异步,都不会立刻将消息发出,Kafka会将消息先保存在内存中,等到合适的时机批量发送给Broker。
在Broker中,整个处理流程同样是义“批”单位处理,无论是写入磁盘,从磁盘读取,复制到其他磁盘,
在Consumer读取消息也是同样以“批”进行传递的,Consumer客户端从Broker获取到一批数据后,再拆分成一条条交由用户代码处理。
顺序读写提升IO读写能力
对于磁盘来说,顺序读取远比随机读取性能要高。
kafka也是利用了磁盘整个特性,对于每个分区,从Producer获取消息后,顺序的写入磁盘log文件,如果某个log文件写满了,则创建新的log文件继续写,读取的时候也是按照分区的log文件顺序读取。
PageCache加速消息读取
计算机文件读取和写入不会直接操作磁盘,中间会有一层PageCache缓存,是OS对文件的缓存,用于加速对文件的读写,当读取是PageCache中没有则会从磁盘中读取,否则直接从PageCache中读取,然后再加载到PageCache中,下次就能直接从PageCache中回去到。
PageCache减少了文件的I/O操作,提高了性能。
零拷贝
零拷贝就是从PageCache将数据直接读到Broker的Socket的Buffer中,在通过网络传输。中间不需要经过程序处理。减少磁盘I/O
延迟消费
Kafka本身不支持延迟消息,通过Kafka Streams实现